学习目标:PHP语言
学习目标:
1、 学习php语言,对常用函数及其参数进行总结;
2、 比较echo,print,var_dump异同;
3、了解bash和shell。
学习内容:
一、php简介
1、php定义:即“超文本预处理器”,是在服务器端执行的脚本/编程语言,尤其适用于Web开发并可嵌入HTML中。PHP语法利用了C、Java和Perl,该语言的主要目标是允许web开发人员快速编写动态网页。
2、php用途:动态网站的开发
二、网站
1、静态网站
①静态网站的内容相对稳定,因此容易被搜索引擎检索;
②网站更安全,HTML页面不会受Asp相关漏洞的影响;而且可以减少攻击,防SQL注入。数据库出错时,不影响网站正常访问;
③减轻了服务器的负担,工作量减少,也就降低了数据库的成本;
④静态网页的交互性较差,在功能方面有较大的限制。
2、动态网站
①动态网站并不是指具有动画功能的网站,而是指网站内容可根据不同情况动态变更的网站,一般情况下动态网站通过数据库进行架构;
②动态网站可以实现交互功能,如用户注册、信息发布、产品展示、订单管理等等;
③动态网页中包含有服务器端脚本,所以页面文件名常以asp、jsp、php等为后缀。但也可以使用URL静态化技术,使网页后缀显示为HTML。所以不能以页面文件的后缀作为判断网站的动态和静态的唯一标准;
④动态网页网址中有一个标志性符号–“?”。
3、网站基本概念
①服务器:
<1> 服务器也称伺服器,是提供计算机服务的设备。由于服务器需要响应服务请求,并进行处理,因此一般来说服务器应具备承担服务并且保障服务的能力;
<2>服务器的构成包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似,但是由于需要提供可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高;
<3>在网络环境下,根据服务器提供的服务器类型不同,分为文件服务器,数据库服务器,应用程序服务器,WEB服务器。
②IP概念:Internet Protocol,网络之间互联协议。网络之间互连的协议也就是为计算机网络相互连接进行通信而设计的协议。
③域名(Domain Name),是由一串用点分隔的名字组成(www.itcast.cn)的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位
举例:IP:127.0.0.1 域名:localhost
④DNS:(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网。
域名解析:用户输入域名,DNS会转换域名为IP,从而找到服务器。
4、Web程序的访问流程

①用户在浏览器地址栏输入请求URL,发起请求。
②通过DNS服务器解析出IP地址,找到对应的主机。
③根据脚本的类型:
如果是以.html结尾的文件,直接返回给浏览器。
如果是以.php结尾的文件,需要先执行PHP脚本。
此外,执行PHP脚本过程中,可能需要连接数据库获取一些数据信息。
所有代码执行完后,Apache将执行结果发给浏览器进行展示。
三、php基础
1、php语法初步:php是一种运行在服务器端的脚本语言,可以嵌入到HTML中。
2、php代码标记:脚本标记:<script language=”php>php 代码
标准标记:
3、php注释:
①行注释:一次注释一行 //
②块注释:一次注释多行 /* 中间直到 */
4、php语句分隔符
语句分隔符:在php中,代码以行为单位系统需要通过判断行的结束,该结束通常都是一个符号:分号“;”(英文状态下的分号)
特殊说明:
1.PHP中标记结束符?>自带语句结束符的效果,最后一行PHP代码可以没有语句结束符;
2、PHP中其实很多代码的书写并不是嵌入到HTML中,而是单独存在,通常书写习惯中不建议使用标记结束符?>


5、变量
PHP是一种动态网站开发的脚本语言,动态语言特点是交互性,会有数据的传递,而PHP作为“中间人”,需要进行数据的传递,传递的前提就是PHP能自己存储数据(临时存储)
①变量是用来存储数据的;
②变量是存在名字的;
③ 变量是通过名字来访问的;
④变量是可以改变的。
6、变量的使用
①定义:在系统中增加对应的变量名字(内存)
②赋值:可以将数据赋值给变量名(可以在定义的同时完成)
③可以通过变量名访问存储的数据
④变量可以从内存中删除。

7、变量命名规则
①在PHP中变量名字必须以“$”符号开始;
②名字由字母、数字和下划线“_”构成,但是不能以数字开头;
③在PHP中本身还允许中文变量(不建议)。
8、预定义变量
预定义变量:提前定义的变量,系统定义的变量,存储许多需要用到的数据(预定义变量都是数组)
$_GET:获取所有表单以get方式提交的数据
$_POST:POST提交的数据都会保存在此
$_REQUEST:GET和POST提交的都会保存
$GLOBALS:PHP中所有的全局变量
$_SERVER:服务器信息
$_SESSION:session会话数据
$_COOKIE:cookie会话数据
$_ENV:环境信息
9、可变变量
可变变量:如果一个变量保存的值刚好是另外一个变量的名字,那么可以直接通过访问一个变量得到另外一个变量的值:在变量前面再多加一个$符号。
$a = ‘b’;
$b = ‘bb’;
$$a->bb

10、变量传值
①定义:将一个变量赋值给另外一个变量:变量传值
②变量传值一共有两种方式:值传递,引用传递
<1>值传递:将变量保存的值赋值一份,然后将新的值给另外一个变量保存(两个变量没有关系)

<2>引用传递:将变量保存的值所在的内存地址,传递给另外一个变量:两个变量指向同一块内存空间(两个变量是同一个值)
$新变量 = & $老变量; (&地址符号)

11、内存
在内存中,通常有以下几个分区
栈区:程序可以操作的内存部分(不存数据,运行程序代码),少但是快
代码段:存储程序的内存部分(只存储代码不执行代码)
数据段:存储普通数据(全局区和静态区)
堆区:存储复杂数据,大但是效率低
12、常量
①常量基本概念:
常量:const/constant,是一种在程序运行当中,不可改变的量(数据)
常量一旦定义,通常数据不可改变(用户级别)
②常量定义形式
在PHP中常量有两种定义方式(5.3之后才有两种)
<1>使用定义常量的函数:define(‘常量名’,常量值);
<2>5.3之后才有的:const 常量名 = 值;
③常量名字的命名规则
<1>常量不需要使用“$”符号,一旦使用系统就会认为是变量;
<2>常量的名字组成由字母、数字和下划线组成,不能以数字开头;
<3>常量的名字通常是以大写字母为主(与变量以示区别);
<4>(第二点不完全对:)常量命名的规则比变量要松散,可以使用一些特殊字符,该方式只能使用define定义
常量在定义时必须要赋值
13、系统常量
系统常量:系统帮助用户定义的常量,用户可以直接使用
常用的几个系统常量
PHP_VERSION:PHP版本号
PHP_INT_SIZE:整型大小。(1字节8位。32位4字节,64位8字节)
PHP_INT_MAX:整型能表示的最大值(PHP中整型是允许出现负数:带符号)
14、数据类型
①定义:数据类型:data type,在PHP中指的是存储的数据本身的类型,而不是变量的类型。PHP是一种弱类型语言,变量本身没有数据类型。
②分类:
简单(基本)数据类型:4个小类
<1>整型:int/integer,系统分配4个字节存储,表示整数类型(有前提)
<2>浮点型:float/double,系统分配8个字节存储,表示小数或者整型存不下的整数(比如32位存不下的整型)
<3>字符串型:string,系统根据实际长度分配,表示字符串(引号)
<4>布尔类型:bool/boolean,表示布尔类型,只有两个值:true和false
复合数据类型:2个小类
<5>对象类型:object,存放对象(面向对象)
<6>数组类型:array,存储多个数据(一次性)
特殊数据类型:2个小类
<7>资源类型:resource,存放资源数据(PHP外部数据,如数据库、文件)
<8>空类型:NULL,只有一个值就是NULL(不能运算)
15、类型转换
①定义:类型转换:在很多的条件下,需要指定的数据类型,需要外部数据(当前PHP取得的数据),转换成目标数据类型
在PHP中有两种类型转换方式:
②分类<1> 自动转换:系统根据需求自己判定,自己转换(用的比较多,系统自己判断需要的类型,效率偏低)
<2>强制(手动)转换:认为根据需要的目标类型转换
强制转换规则:在变量之前增加一个括号(),然后在里面写上对应类型:int/integer….其中NULL类型用到unset()
在转换过程中,用的比较多的就是转布尔类型(判断)和转数值类型(算术运算)
其他类型转布尔类型:true或者false,在PHP中比较少类型会变成false
说明:其他类型转数值的说明
1)布尔true为1,false为0;
2)字符串转数值有自己的规则
3)以字母开头的字符串,永远为0;
4)以数字开头的字符串,取到碰到字符串为止(不会同时包含两个小数点)
16、运算符
①赋值运算:符号是“=”,表示将右边的结果(可以是变量、数据、常量和其它运算出来的结果),保存到内存的某个位置,然后将位置的内存地址赋值给左侧的变量(常量)。
②算术运算:基本算术操作
+:执行数据累加
-:数据相减
:键盘上没有乘法符号,使用代替,两个数相乘
/:正斜杠代替,表示两个数相除
%:取余(模)运算,两个数(整数)相除,保留余数
在进行除法运算或者取余运算的时候,对应的除数(第二个数)不能为0
③比较运算:比较两个数据的大小,或者两个内容是否相同,返回的结果都是布尔类型:满足返回true,不满足返回false
:左边大于右边,返回结果true
=:左边大于等于右边
<:左边小于右边
<=:左边小于或者等于右边
==:左边的与右边的相同(大小相同)
!=:左边的与右边的不同(大小不同)
===:全等于,左边与右边相同:大小以及数据的类型都要相同
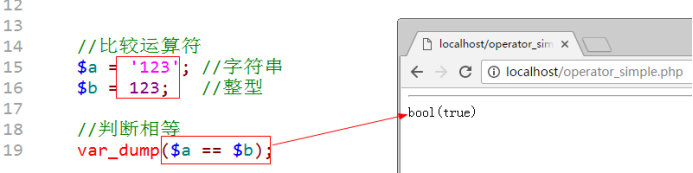

④逻辑运算:针对不同的结果进行匹配。满足条件返回true,不满足返回false
&&和and:逻辑与,左边的条件与右边的条件同时成立(两边结果都为true)
||和or:逻辑或,左边的条件或者右边的条件只要有一个满足即可
!:逻辑非,对已有条件进行取反,本身为true,取反结果就是false

逻辑与和逻辑或又称之为短路运算:如果第一个表达式结果已经满足条件了,那么就不会运行逻辑运算符后面的表达式:在书写代码的时候,尽量将出现概率最高的(能够直接判断出结果)的表达式放到第一位,提高运算效率
17、连接运算符
连接运算:是PHP中将多个字符串拼接的一种符号
. :将两个字符串连接到一起
.= : 复合运算,将左边的内容与右边的内容连接起来,然后重新赋值给左边变量
A .= b ⇔ A = A . b

18、自操作运算符
自操作:自己操作自己的运算符
++:在原来的值上+1
–:在原来的值上-1
$a = 1;
$a++; // $a = $a + 1;
在PHP中自操作符是可以放到变量前或者后:前置自操作和后置自操作
$a = 1;
$a++;
++$a; //前置或者后置如果本身只有自操作,不参与其他运算(自操作同时),那么效果是一样的。但是如果自操作同时还参与别的运算,那么效果就不一样
$a = 1;
$b = $a++; //$a++会导致$a = $a + 1; $a = 2;,上面的$b = 1
$c =++$a; //++$a会导致$a = $a + 1; $a = 2;,$c = 2;
后置自操作:先把自己所保存的值留下来,然后改变自己,自己给别人的值是原来的值;
前置自操作:先把自己改变,然后把改变后的值给别
与c 语言类似
19、常用函数总结
1、输出函数
print():类似于echo输出提供的内容,本质是一种结构(不是函数),返回1,可以不需要使用括号(因为是结构不是函数)
print_r():类似于var_dump,但是比var_dump简单,不会输出数据的类型,只会输出值(数组打印使用比较多)
而var_dump()是判断一个变量的类型与长度,并输出变量的数值,如果变量有值,则输出是变量的值,并返回数据类型。
echo函数实际不是一个函数,可以连续输出多个变量,而print一次只能输出一个
2、有关时间的函数

date():按照指定格式对对应的时间戳(从1970年格林威治时间开始计算的秒数)转换成对应的格式,如果没有指定特定的间时间戳,那么就是默认解释当前时戳
time():获取当前时间对应的时间戳
microtime():获取微秒级别的时间

3、有关数学的函数
max():指定参数中最大的值
min():比较两个数中较小的值
rand():得到一个随机数,指定区间的随机整数
mt_rand():与rand一样,只是底层结构不一样,效率比rand高(建议使用)
round():四舍五入
ceil():向上取整
floor():向下取整
pow():求指定数字的指定指数次结果:pow(2,8) == 2^8 == 256
abs():绝对值
sqrt():求平方根
4、有关函数的函数
function_exists():判断指定的函数名字是否在内存中存在(帮助用户不去使用一个不存在的函数,让代码安全性更高)
func_get_arg():在自定义函数中去获取指定数值对应的参数 – 实参位置
func_get_args():在自定义函数中获取所有的参数(数组)– 所有实参
func_num_args():获取当前自定义函数的参数数量 – 实参数量

5、字符串相关函数
1)转换函数:implode(), explode(), str_split()
implode(连接方式,数组):将数组中的元素按照某个规则连接成一个字符串
explode(分割字符,目标字符串):将字符串按照某个格式进行分割,变成数组
中国|北京|顺义 == array(‘中国’,‘北京’,’顺义’);
str_split(字符串,字符长度):按照指定长度拆分字符串得到数组
2)截取函数:trim(), ltrim(), rtrim()
trim(字符串[,指定字符]):本身默认是用来去除字符串两边的空格(中间不行),但是也可以指定要去除的内容,是按照指定的内容循环去除两边有的内容:直到碰到一个不是目标字符为止
ltrim():去除左边的
rtrim():去除右边的
3)截取函数:substr(), strstr()
substr(字符串,起始位置从0开始[,长度]):指定位置开始截取字符串,可以截取指定长度(不指定到最后)
strstr(字符串,匹配字符):从指定位置开始,截取到最后(可以用来取文件后缀名)
4)大小转换函数:strtolower(), strtoupper(), ucfirst()
strtolower:全部小写
strtoupper:全部大写
ucfirst:首字母大写
5)查找函数:strpos(), strrpos()
strpos(字符串,匹配字符):判断字符在目标字符串中出现的位置(首次)
strrpos(字符串,匹配字符):判断字符在目标字符串中最后出现的位置
6)格式化函数:printf(), sprintf()
srintf/sprintf(输出字符串有占位符,顺序占位内容…):格式化输出数据
7)其他:str_repeat(), str_shuffle()
str_repeat():重复某个字符串N次
str_shuffle():随机打乱字符串




 四、数字型与字符型
四、数字型与字符型
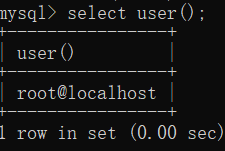
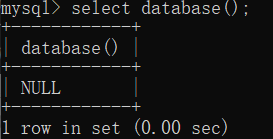
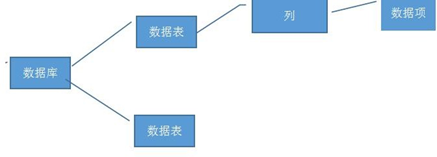
 一、定义:MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言–结构化查询语言(SQL)进行数据库管理。(关于
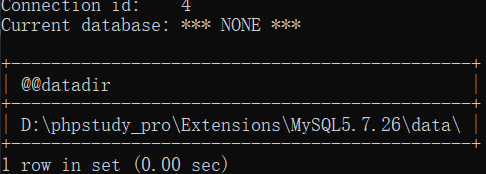
一、定义:MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言–结构化查询语言(SQL)进行数据库管理。(关于 3、mysql命令行的打开
3、mysql命令行的打开 <3>在cmd内输入
<3>在cmd内输入









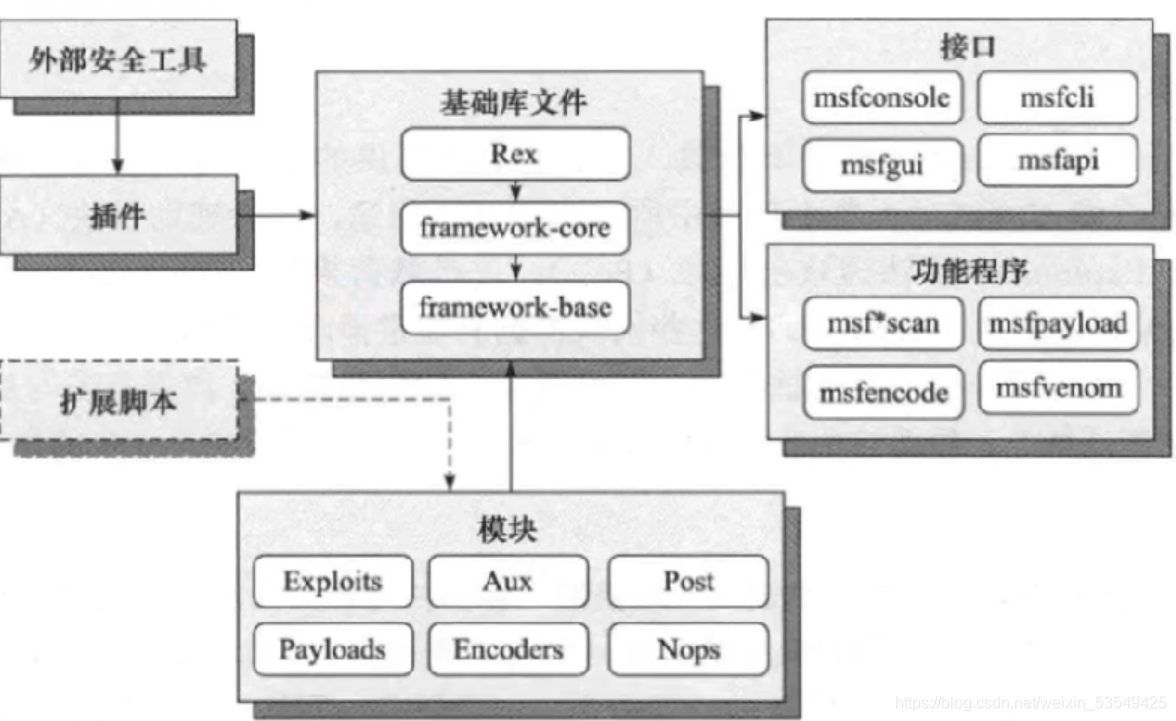
 data是Metasploit使用的可编辑文件
data是Metasploit使用的可编辑文件










